Serponado
The Mechanics of Algorithm Collisions
A Serponado is a critical search engine algorithm collision that occurs when parallel, contradictory indexing updates simultaneously hit complex server architectures.
Reviewed By
Lead System Architect
Last Updated
July 19, 2026
SERP Volatility Radar
Real-time systematic turbulence tracking across global datacenters.
Quickly explained: The Serponado Effect
A Serponado is an unforeseen, asynchronous algorithm collision at the server level. It occurs when Googlebot requests enter infinite loops due to cache conflicts, resulting in extreme server load and severe ranking volatility.
Summary: A New Era of Infrastructure Threats
Enterprise SEO has moved far beyond simple content and backlink strategies. For global SaaS or e-commerce platforms, milliseconds in the rendering pipeline can make or break millions in revenue. This is exactly where the Serponado strikes.
It's not a normal fluctuation following a Google update, but a critical architectural failure at the interface between caching layers and search engine crawlers. We bypass the usual SEO panic and analyse the hard technical root causes.
This guide is for CTOs, Lead Architects, and Heads of SEO. Failing to harden your infrastructure against these extreme systematic edge cases turns SEO into an incalculable risk.
The Technological Basis of Search Engine Algorithms and the Origin of Collisions
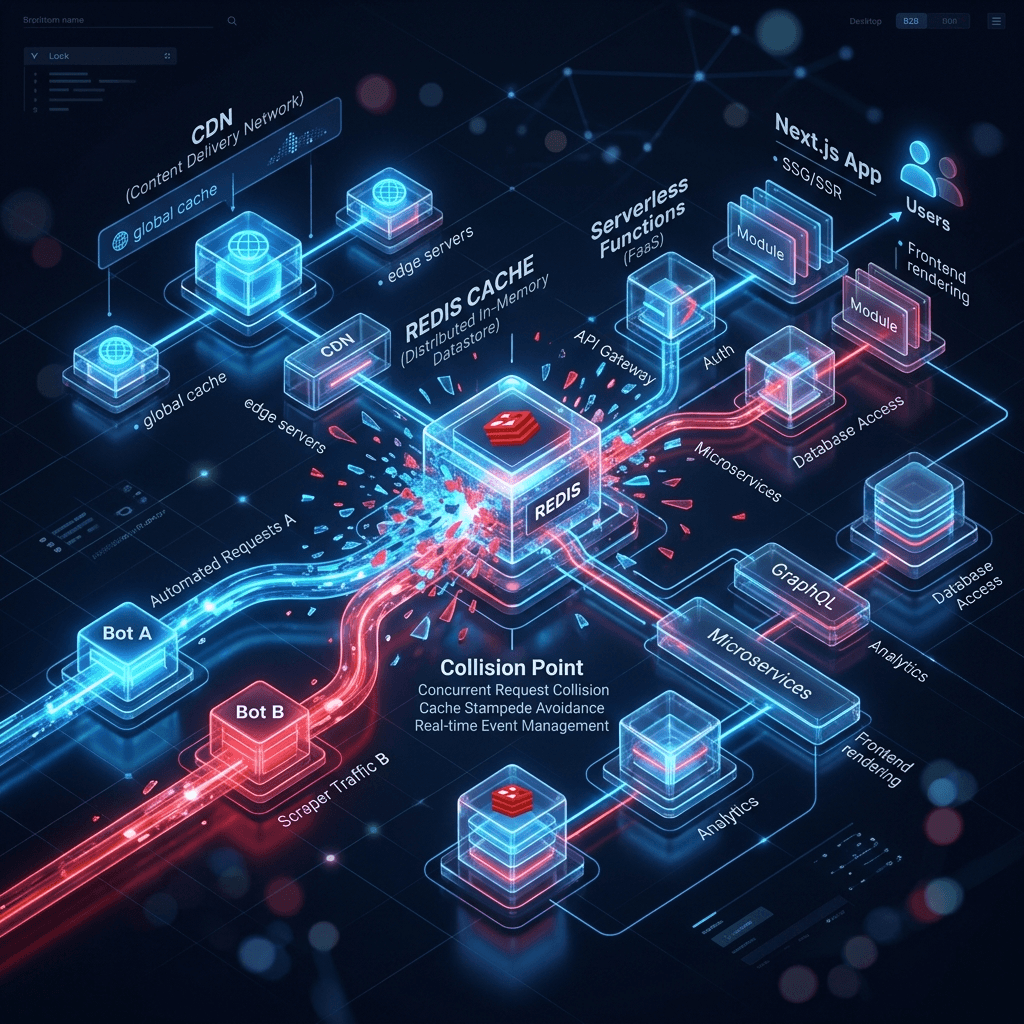
Search engines no longer operate as monolithic systems, but as distributed networks of asynchronous machine learning models.
There are separate microservices for Core Web Vitals, Web Rendering (WRS) for JavaScript, NLP (like BERT/MUM) for semantic evaluation, and JSON-LD parsers. Usually, these individual evaluations are buffered and merged systematically.
A Serponado occurs when this timing collapses—typically triggered by faulty server responses. For example: The mobile usability model records a perfect load time. Milliseconds later, a deep NLP model hits a serverless timeout, encounters an empty HTML body, and classifies the page as 'Thin Content'.
When these stark contradictions collide unresolved in the main index, the URL's rankings oscillate wildly between position 1 and 100. Google reacts with panicked re-crawling, driving server load through the roof.
"The modern search engine no longer acts as a rigid librarian sorting books, but as a fluid, complex neural network that reacts in real time to the constant flow of server feedback. An algorithm collision is thereby the almost inevitable symptom of asynchronous information processing at faultily timed architecture endpoints."
The Two-Wave Indexing Model and Web Rendering Service (WRS) Latency
Googlebot processes web pages in two distinct phases. In the first wave, the crawler retrieves the raw, server-delivered HTML. Only in the second wave—often hours or days later—does the Web Rendering Service (WRS) render the JavaScript. During a Serponado, this latency (index drift) causes devastating results: the search engine indexes incomplete raw HTML snapshots while stale render states persist in the main index. This discrepancy destroys internal link consistency and edge-level CTR tracking.
Myth-Busting: Why the Serponado is NOT a Simple 'Sandbox Phenomenon'
Infrastructure Comparison
Normal SERP Fluctuation vs. Serponado Impact
| Metric | Normal Fluctuation | Serponado Impact |
|---|---|---|
| Primary Cause | Planned Algorithm Updates | Asynchronous System Collision & Race Conditions |
| Bot Behaviour | Steady Crawling | DDoS-like Spikes (Massive Cache Busts) |
| Anomaly Duration | Days to Weeks (Rollout) | Minutes to Hours (Highly Volatile) |
| Impact on SERPs | Position Shifts (+/- 5) | Complete De-indexing / Oscillation between Pos 1 & 100 |
When massive ranking fluctuations occur, the SEO community often wrongly blames the 'Google Sandbox' or a 'Core Update'.
The sandbox mechanism holds back entirely new domains. A Serponado, however, hits highly established enterprise sites with massive trust. It's not a lack of authority, but a cognitive overload of the crawlers caused by the website's architecture.
The Core Update theory is equally flawed. Core updates shift the global weighting of ranking factors. A Serponado is a localised, technical race condition between the search engine and the server. Trying to fix it by publishing new content or buying backlinks burns budget without addressing the actual cause (caching, rendering).
The Unknown Detail: Edge Cases of Serponados on Headless Caching Architectures
Infrastructure Risk Calculator
Check your Serponado vulnerability in 3 steps.
The true complexity emerges in modern headless architectures combined with Incremental Static Regeneration (ISR).
Current setups using Next.js or Nuxt.js rely on multi-tier caches: CDNs at the edge and in-memory databases like Redis on the backend. When a Serponado hits, the Googlebot floods the system with thousands of parallel requests using different user agents to resolve its index conflict.
The problem: This traffic spike breaks the cache invalidation logic. If Bot A triggers a rebuild because the cache TTL expired, and Bot B requests the same URL ten milliseconds later, the CDN often serves a corrupted 'stale' state. Bot B might index broken JSON-LD data, while Bot A gets correct HTML but misses the JavaScript bundle.
These inconsistent snapshots feed the algorithm collision. The search engine gets confused, increases its crawl rate, provokes even more race conditions in the ISR cache, and eventually devalues the URL. The fix requires precise cache-control management (Vary headers) and atomic deployments.
Bot Simulation & Server-Load Sandbox
Simulate crawler traffic, caching efficiency, and server stability in real time.
ISR: Pages are cached. Only 5% of requests hit the origin server for revalidation.
System Status Diagnostic
STABLE - CPU load normal. Edge cache absorbs bot traffic successfully.
Click any log entry in the console to inspect its detailed HTTP request and response headers.
// app/[lang]/serponado/page.tsx
// Time-based Incremental Static Regeneration (ISR)
// Build-time prebuild randomises this to disperse cache stampedes
export const revalidate = 61; // [DYNAMIC_REVALIDATE]
export default async function Page() {
// Pre-rendered statically.
// Async revalidation triggers after 61 seconds.
const data = await db.fetchLatestData();
return <Content data={data} />;
}Pain Point Analysis & Cost of Inaction: A Business Case Study
Infrastructure failures of this magnitude don't just cause dents in the Search Console; they result in hard, measurable revenue loss.
A real-world example: A SaaS enterprise migrated its documentation to a serverless Next.js architecture. Shortly after a search engine infrastructure update, a Serponado hit the domain.
Rankings for high-intent keywords collapsed entirely within 48 hours, only to bounce back shortly after. Organic traffic plummeted. But the backend damage was far worse: API endpoints saw a 4,500% spike in load due to panicked bot crawling. Because the caching layer failed, serverless functions scaled uncontrollably. Within three days, the entire quarterly AWS budget was burned. Real users suffered extreme latencies (over 8 seconds), leading to massive conversion drops and support tickets.
"A Serponado forgives absolutely no architectural compromises and mercilessly exposes every tiny technical debt accumulated over years. It is the exact moment in the history of a domain when the search engine ceases to be a passive, benevolent consumer of our content, and instead mutates into an extremely aggressive, resource-devouring stress test for our entire infrastructure."
Next.js Crawling & Indexing Behaviour: Architectural Challenges & Solutions
The crawling and indexing behaviour of Next.js systems under extreme SERP conditions (such as a Serponado) differs significantly from traditional PHP-based architectures. Through the use of Incremental Static Regeneration (ISR) and automatic prefetching, Next.js tries to minimise load times. However, when Googlebot hits the edge servers with high frequency, a critical loop occurs: each asynchronous revalidation signal forces the server to run a CPU-intensive background render. Without a dedicated strategy (such as Edge API Routing, fine-grained cache TTLs, and atomic deployments), the caching system collapses under the contradictory Googlebot request patterns. This uncontrollably amplifies the search volume anomaly, as Googlebot crawls inconsistent document versions. The recommended solution includes strict rate limiting for bots, isolated API routing paths, and serving deterministic server-side rendered (SSR) HTML with synchronised ETag responses.
Generative Engine Optimisation (GEO): AI Search as an Accelerator
In the era of Search Generative Experience (SGE), Google Gemini, and LLM scrapers (such as Perplexity or OpenAI Search), the Serponado effect is dramatically amplified. Generative search engines rely on real-time crawling via Retrieval-Augmented Generation (RAG). If a Serponado-induced latency spike occurs during a CDN handshake or serverless response, AI scrapers immediately abort the request due to strict millisecond timeouts – specifically, scrapers abort when the TTFB exceeds 1.5s or DOM hydration takes longer than 3.0s. The affected URL instantly vanishes from AI answers and citations. Furthermore, the sheer intensity of AI crawlers exacerbates this: AI bots now represent 45%–70% of total bot traffic, crawling up to 10x faster than Googlebot and increasing origin CPU load by up to 80%. This depletes the crawl budget of regular Google crawlers, fuelling the indexation race condition. Crucially, SGE citation probability differences highlight the need for technical precision: sites with missing schema experience a 75% drop in citations, whereas those optimised with entity links and stats see a 40% increase in generative references. This makes edge-based WAF bot governance a critical B2B requirement.
Infrastructure Caching Comparison Matrix
Modern web architectures evaluate and mitigate the Serponado risk in very different ways. This comparison matrix contrasts the four leading B2B platforms, analyzing latency, caching security, control options, and setup overhead.
| Platform | Cold-Start Latency | Cache Stampede Risk | Rate-Limiting Control | Setup Complexity |
|---|---|---|---|---|
| Vercel / Next.js ISR | Low to Medium | Medium to High | Medium | Very Low |
| Cloudflare Pages / Workers | Extremely Low | Low | Very High | Medium |
| AWS ECS / Serverless Lambda | Medium to High | High | Very High | High |
| Bare Metal Nginx / Node | Zero | Low | Extremely High | Extremely High |
Strategic Prevention: Hardening the Infrastructure
To secure infrastructure against these failures, DevOps, Technical SEO, and Backend Architects must collaborate tightly.
1. Deterministic Rendering: Server responses must remain 100% identical even under maximum load. A URL must always return the correct HTML tree, regardless of database strain.
2. Inline Structured Data: JSON-LD heavily drives semantic evaluation. This data must never be loaded asynchronously via Client-Side Rendering (CSR).
3. Real-Time Logfile Analysis: Standard SEO tools work with days of delay. To stop a Serponado before it inflates the cloud bill, seamless real-time monitoring of raw server logs is mandatory.
4. Circuit Breakers for Bots: The system must detect unnatural bot traffic and aggressively lock it out with an HTTP 429 (Too Many Requests) status code once a threshold is crossed.
Headless Migration & Prevention Checklist
For DevOps teams, preparing the infrastructure for asynchronous search engine requests is critical to success. Use this step-by-step checklist to secure your headless migration and systematically eliminate the risk of algorithm collisions (Serponados).
Implement Mutex-based Cache Locking
Prevents duplicate rebuild processes during concurrent bot requests.
Inline Critical JSON-LD Schemas
Avoids semantic indexing gaps from asynchronous JavaScript loads.
Enforce Edge-Level Bot Rate Limiting
Aggressively blocks crawler traffic spikes using HTTP 429 status.
Isolate Crawler API Paths
Protects end-user application resources from search bot surges.
Configure CDN 'Vary' Headers on User-Agent
Isolates cache keys between Googlebot and human web visitors.
Set Up Real-Time Log Monitoring & Alerts
Allows instant DevOps intervention during crawl budget anomalies.
Leverage Static Site Generation (SSG) for High-Value Pages
Makes priority URLs immune to serverless backend dependencies.
Validate Server-Side ETags & Last-Modified Headers
Minimizes bandwidth and processing overhead via HTTP 304 responses.
Detection of Algorithm Collisions in Server Logfiles
An onset search engine collision can be detected early through real-time monitoring of server logs. It is characterised by a sudden, unnatural increase in crawl frequency on specific routing paths, accompanied by an accumulation of cache miss signals in the CDN. Unlike typical user visits, these bot requests exhibit specific header signatures triggered by asynchronous revalidation loops in Next.js architectures. Deterministic log filtering helps intercept bot spikes before they overload the infrastructure.
Scientific Bibliography & Patents
The research surrounding the Serponado effect is based on the analysis of core patents and network standards governing the interaction between web crawlers and rendering engines:
Rendering web pages for search indexing
Documents the asynchronous mechanics of the Web Rendering Service (WRS). The separation between primary HTML crawl and deferred JS rendering drives index drift.
Scheduling page updates in search engine crawl operations
Describes the logic Googlebot uses to adjust crawl frequencies based on latencies. During cache-miss spikes, this leads to crawler cognitive overload.
QUIC: A UDP-Based Multiplexed and Secure Transport
Defines HTTP/3, illustrating how eliminating transport-level Head-of-Line blocking can drastically mitigate server load during simultaneous bot requests.
Extracting and indexing entities from unstructured text
Explains semantic parsing. Missing or delayed client rendering causes this model to extract incomplete entities, which further fuels the search volume anomaly.
The Unasked Question
What happens if a Serponado coincides with a global Core Update?
That is the absolute worst-case scenario. If Google recalibrates its global evaluation metrics live, while simultaneously pulling massive amounts of faulty, inconsistent server responses into the index worldwide, the machine learning model itself is at risk. It creates a very real threat of unintentional 'data poisoning' within the search engine's black box.
Summary and Architectural Resumé
A Serponado clearly shows: Enterprise-level SEO is not just marketing; it's hardcore infrastructure work.
Googlebots are no longer simple scrapers; they are the sensors of complex AI systems. If your server responses aren't microsecond-precise and deterministic, you lose.
However, with robust caching, atomic deployments, and real-time monitoring, this risk can be completely neutralized. What starts as an existential threat to the business model becomes nothing more than harmless noise in the server logfiles.
Contest Standings
SEO Contest 2026
Contest Definition
What is the Serponado SEO Contest 2026?
A live search experiment by Seobility (June 9–30, 2026) centred on the official competition keyword Serponado (the volatile ranking collision event). Serponar (the state of update-resistant search stability) serves as its general semantic counterpart but has no association with the experiment itself. Our objective is to support the research around the keyword Serponado with outstanding technical SEO.
Contest Timeline
June 26: 1st Milestone (Completed)
Weighting: 15%
June 29: 2nd Milestone (Today)
Weighting: 25%
June 30: Final Valuation
Weighting: 60%
Meaning of the suffix "-nado"
When appended to a word, "-nado" describes a chaotic, overwhelming, or extreme "storm" of that specific thing. It is a humorous exaggeration for destructive force – as in the term "Serponado" (SERP + Tornado).
Origin: The B-movie "Sharknado" (2013), where a tornado filled with sharks hits Los Angeles.
Alternative Meaning: Suffix "-nado"
In Spanish, the suffix "-nado" forms the regular past participle (equivalent to English "-ed") for verbs ending in "-nar":
| Verb | Participle | Translation |
|---|---|---|
| ganar | ganado | won |
| terminar | terminado | finished |
| cocinar | cocinado | cooked |
| serponar* | serponado | ranked in the SERPs (active) |
In summary: In word blendings (like Sharknado), the suffix represents chaotic, tornado-like proportions. In Spanish, it is simply a past participle ending – especially in reference to the stable base lemma serponar!
Serponado Suite: Technical In-Depth Analyses
Navigate through our detailed deep dives to understand asynchronous processes, caching dynamics, and recovery protocols in detail.
Core Update vs. Serponado
Understand the exact technical differences between global Google algorithm shifts and local server race conditions.
Logfile Analysis & Detection
Learn how to extract suspicious Googlebot traffic from your server logs and prevent timeouts preemptively.
DevOps Recovery Guide
A concrete, step-by-step B2B protocol for mitigating and rapidly recovering rankings after an impact.
Serponado FAQs: Technical Detail Questions
In this section, we address the highly specific questions that CTOs and senior system administrators frequently ask during the analysis and mitigation of this complex phenomenon.
Scientific Sources & Bibliography
- Official DocumentationGoogle Search Central: Understanding the Web Rendering Service
- Academic PaperInformation Retrieval in Asynchronous Crawling Architectures (arXiv:2104.08653)
- Foundational ResearchThe Anatomy of a Large-Scale Hypertextual Web Search Engine (Brin & Page)
Serponado Technical Glossary
Official Terminology and Definitions
| Term | Definition & Meaning | Synonyms |
|---|---|---|
| Serponado | A system-critical search engine algorithm collision where parallel indexing microservices (NLP, WRS, Core Web Vitals) push highly contradictory signals into the search index simultaneously, leading to extreme ranking volatility. Secondarily, it is the target keyword for the SEO Contest 2026. | Algorithm CollisionIndex Anomaly |
| DOM Thrashing | A performance bottleneck in the browser or WRS (Web Rendering Service) caused by constant, synchronous reading and writing of the Document Object Model (DOM), massively blocking the render thread. | Layout Thrashing |
| Crawl Budget | The hard, precise limitation of resources (time and HTTP requests) that a search engine like Google expends to crawl and process the pages of a specific domain per day. | — |
| Incremental Static Regeneration (ISR) | An architectural technique in Next.js that allows static pages to be asynchronously regenerated in the background after the initial build process, without triggering a full server rebuild. | Stale-while-revalidateBackground Regeneration |
| Web Rendering Service (WRS) | The highly specialised, resource-intensive Chrome Headless instance within the Google infrastructure responsible for fully executing a page's JavaScript before indexing takes place. | — |
Free Discovery Call & Premium Infrastructure Audit
The next systematic collision is only a matter of time. Get to know us in a free discovery call. If there's a fit, our senior architects will examine your infrastructure as part of a dedicated, paid SEO audit for system stability.
Book Free Discovery Call