The Hidden Danger of ISR Caching in Modern Headless Architectures
While Next.js and headless architectures provide speed, poor ISR caching logic during bot surges can severely damage enterprise SEO. Learn how to prevent SWR rendering conflicts.
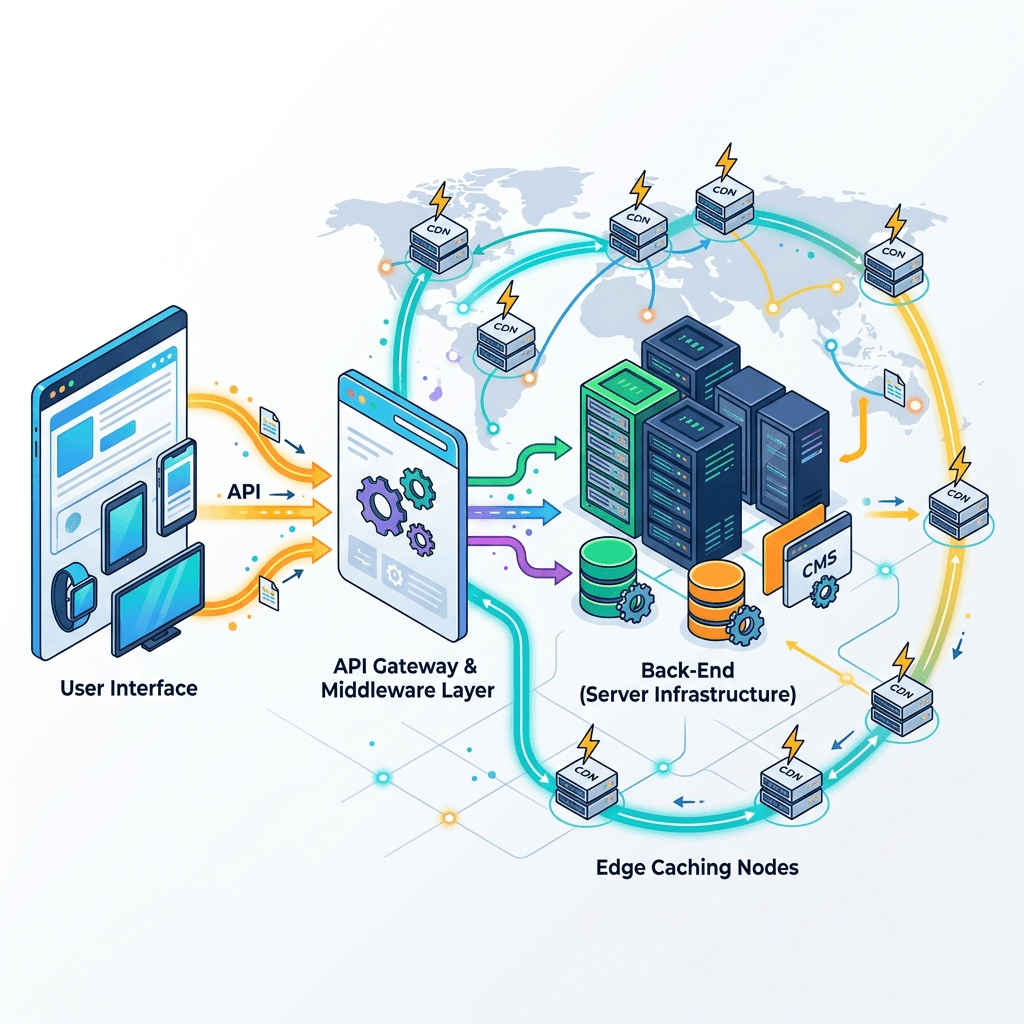
In the contemporary landscape of enterprise web development, the migration towards decoupled headless architectures—particularly utilizing Next.js—has become the gold standard. Chief Technology Officers and Lead Architects correctly identify Incremental Static Regeneration (ISR) as the optimal mechanism to balance rapid Time to First Byte (TTFB) with dynamic data injection. However, an insidious architectural flaw often remains undetected until disaster strikes: the hidden danger of ISR caching under the strain of extreme bot traffic.
When evaluating system resilience, human traffic patterns are relatively predictable. Bots, particularly search engine crawlers evaluating a site during a massive indexation sweep, operate differently. This article dissects the devastating rendering conflicts triggered by SWR (Stale-While-Revalidate) misconfigurations, the catastrophic impact of cache invalidation failures on Technical SEO, and how to safeguard your headless infrastructure.
The Illusion of Infinite Scalability
Headless architectures decouple the presentation layer (React/Next.js) from the backend database or CMS. ISR allows developers to create static pages at build time and update them in the background as traffic arrives. The premise is flawless: serve a lightning-fast static file from the CDN Edge, while a serverless function quietly rebuilds the page with fresh data.
But what happens when Googlebot initiates a massive, concurrent crawl of 50,000 URLs following an architectural shift or a major algorithm update? (To understand the mechanics of these events, explore our detailed analysis of the algorithmic storm known as Serponado).
The ISR Race Condition
Time-based ISR relies on a revalidate timer (e.g., 60 seconds). When a bot requests a page after the 60 seconds have elapsed, it receives the stale page. This request simultaneously triggers a background rebuild.
If search engines are aggressively crawling your site, they might hit thousands of stale pages simultaneously. This triggers an avalanche of serverless background rebuilds. If your backend database or headless CMS API rate limits these requests, the rebuilds fail. The cache is not updated. Worse, if the serverless functions time out, the crawler might be served a 500 Internal Server Error, instantly decimating your crawl budget.
The SWR Hook Vulnerability
Stale-While-Revalidate (SWR) is a highly popular data-fetching strategy in React. It immediately returns cached data (stale), sends the fetch request (revalidate), and then comes with the up-to-date data.
From a human UX perspective, this is excellent. From a bot's perspective, it is a technical catastrophe.
Crawlers, despite their advancements, do not wait indefinitely for client-side JavaScript hydration to complete. If you are relying on client-side SWR hooks to fetch critical, indexable content (such as pricing tables, product descriptions, or main article text), the bot will often parse the DOM before the SWR hook completes its network request.
The search engine indexes the loading state, or worse, an empty container. You have essentially deployed an invisible website. For SEO, critical content must be injected Server-Side. SWR should strictly be reserved for user-specific, non-indexable data (like shopping cart status or localized inventory).
Cache Invalidation and "Ghost Data"
Perhaps the most frustrating scenario for a Lead Architect is the failure of Cache Invalidation. When a marketing team updates a critical landing page, they expect that change to reflect immediately across the index.
With aggressive CDN caching, Edge caching, and Next.js internal memory caching, invalidating the old state is incredibly complex. If the webhooks between your Headless CMS and your Next.js application misfire, you experience "Ghost Data"—where the old content persists indefinitely at the Edge.
When Googlebot crawls a URL and sees Ghost Data, it creates a discrepancy between the algorithm's understanding of your entities and the reality of your business. If left unchecked during periods of high algorithmic volatility, this can result in catastrophic ranking losses. For mitigation protocols when your site has been compromised by such technical debt, review our established Serponado recovery blueprints.
The Cost of Inaction: Algorithmic Penalties
The financial implications of ignoring these headless caching dangers are severe. An enterprise B2B portal migrating to Next.js without tuning its cache invalidation logic will likely see a short-term boost in Core Web Vitals, followed by a sudden, inexplicable drop in organic visibility.
This drop is not a content issue; it is a structural parsing failure. Search engines lose trust in the domain's architecture. They encounter varying states of the DOM, intermittent 5xx errors from overwhelmed serverless queues, and stale data configurations.
Strategic Solutions for the C-Suite
- Shift to On-Demand Revalidation: Abandon time-based ISR. Implement webhook-triggered, On-Demand Revalidation. The page should only ever rebuild when the specific entry in the CMS is saved or mutated. This completely eliminates unnecessary serverless executions and prevents bot-triggered DDoS-like rebuild surges.
- Edge Bot Detection: Utilize Edge middleware to distinguish between organic user traffic and search engine crawlers. While users can be served via SWR for ultra-fast navigation, bots must be served fully resolved, Server-Side Rendered (SSR) HTML to guarantee perfect indexation.
- Architectural Auditing: Continually monitor log files for crawler behavior. If Googlebot is frequently encountering 304 Not Modified or 500 errors during background rebuilds, your infrastructure is actively fighting the search engine.
Conclusion
Migrating to a headless architecture is a mandatory step for modern enterprise platforms, but it requires profound respect for the complexities of distributed caching. ISR and SWR are not "set-and-forget" features. They are powerful tools that, without meticulous architectural oversight, can sever your connection to the search engine index.
By prioritizing deterministic rendering paths for bots and implementing robust, on-demand cache invalidation pipelines, Lead Architects can ensure their infrastructure remains both lightning-fast and universally comprehensible to the algorithms that govern digital visibility.








![Top 110 SEO Keywords and Terms: Complete Glossary [2026]](/insights/images/hero-keyword-research.png)
