Serponado
La Mécanique des Collisions d'Algorithmes
Un Serponado est une collision critique de l'algorithme des moteurs de recherche qui se produit lorsque des mises à jour d'indexation parallèles et contradictoires frappent simultanément des architectures de serveurs complexes.
Revu par
Architecte Système Principal
Mis à jour
23 juillet 2026
Radar de Volatilité SERP
Suivi en temps réel des turbulences systématiques dans les centres de données mondiaux.
Explication rapide : L'effet Serponado
Un Serponado désigne une collision d'algorithme asynchrone et imprévue au niveau du serveur. Il se produit lorsque les requêtes de Googlebot entrent dans des boucles infinies en raison de conflits de cache, entraînant une charge serveur extrême et une forte volatilité des classements.
Résumé : Une nouvelle ère de menaces infrastructurelles
Le SEO d'entreprise (Enterprise SEO) a largement dépassé les simples stratégies de contenu et de netlinking. Pour les plateformes SaaS ou e-commerce mondiales, quelques millisecondes dans le pipeline de rendu (rendering pipeline) peuvent faire gagner ou perdre des millions de revenus. C'est exactement là que le Serponado frappe.
Il ne s'agit pas d'une fluctuation normale suite à une mise à jour Google, mais d'une défaillance architecturale critique à l'interface entre les couches de cache (caching layers) et les robots d'exploration (crawlers) des moteurs de recherche. Nous dépassons la panique SEO habituelle pour analyser les causes techniques fondamentales.
Ce guide s'adresse aux directeurs techniques (CTOs), aux architectes principaux et aux directeurs SEO (Heads of SEO). Ne pas renforcer votre infrastructure contre ces cas extrêmes d'algorithmes (edge cases) transforme le SEO en un risque incalculable.
La base technologique des algorithmes de recherche et l'origine des collisions
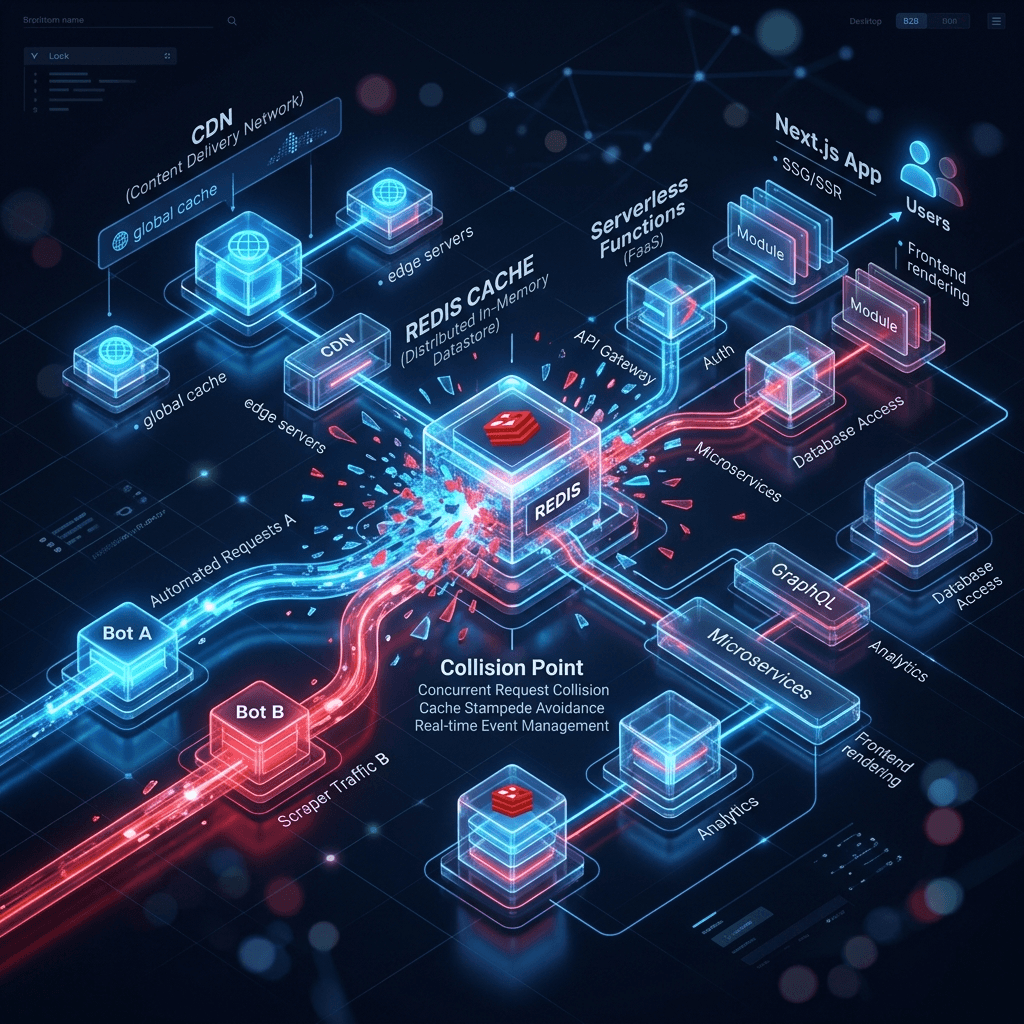
Les moteurs de recherche ne fonctionnent plus comme des systèmes monolithiques, mais comme des réseaux distribués de modèles de machine learning asynchrones.
Il existe des microservices séparés pour les Core Web Vitals, le Web Rendering Service (WRS) pour JavaScript, le traitement du langage naturel (NLP - comme BERT/MUM) pour l'évaluation sémantique, et les analyseurs (parsers) JSON-LD. En général, ces évaluations individuelles sont mises en mémoire tampon et fusionnées de manière systématique.
Un Serponado se produit lorsque cette synchronisation s'effondre—généralement déclenché par des réponses de serveur défectueuses. Par exemple : Le modèle d'ergonomie mobile enregistre un temps de chargement parfait. Quelques millisecondes plus tard, un modèle NLP profond subit un délai d'attente (timeout) serverless, rencontre un corps HTML (body) vide, et classe la page comme 'Contenu pauvre' (Thin Content).
Lorsque ces contradictions flagrantes entrent en collision sans résolution dans l'index principal, les classements (rankings) de l'URL oscillent de manière chaotique entre la position 1 et 100. Google réagit par un re-crawl paniqué, faisant exploser la charge du serveur.
"Le moteur de recherche moderne n'agit plus comme un bibliothécaire rigide classant des livres, mais comme un réseau de neurones fluide et complexe qui réagit en temps réel au flux constant de retours des serveurs. Une collision systématique est ainsi le symptôme presque inévitable d'un traitement de l'information asynchrone au niveau de points de terminaison architecturaux (architecture endpoints) mal synchronisés."
Le modèle d'indexation en deux vagues et la latence du Web Rendering Service (WRS)
Googlebot traite les pages web en deux phases distinctes. Lors de la première vague, le robot d'indexation récupère le code HTML brut fourni par le serveur. Ce n'est que lors de la deuxième vague (souvent des heures ou des jours plus tard) que le Web Rendering Service (WRS) exécute le JavaScript. Lors d'un Serponado, cette latence (dérive d'indexation) produit des résultats critiques : le moteur d'indexation stocke des captures HTML brutes incomplètes, tandis que des états de rendu obsolètes persistent dans l'index principal. Cette divergence détruit la cohérence des liens internes et le suivi du CTR au niveau Edge.
Démystification : Pourquoi le Serponado N'EST PAS un simple 'Phénomène de Sandbox'
Comparaison d'Infrastructure
Fluctuation Normale des SERP vs. Impact Serponado
| Métrique | Fluctuation Normale | Impact Serponado |
|---|---|---|
| Cause Principale | Mises à jour planifiées de l'algorithme | Collision Système Asynchrone & Race Conditions |
| Comportement du Bot | Exploration Régulière | Pics de type DDoS (Cache-Busts massifs) |
| Durée de l'Anomalie | Jours à Semaines (Déploiement) | Minutes à Heures (Hautement Volatil) |
| Impact sur les SERPs | Changements de Position (+/- 5) | Désindexation complète / Oscillation entre Pos 1 & 100 |
Lorsque des fluctuations massives de classement se produisent, la communauté SEO accuse souvent à tort la 'Google Sandbox' ou une 'Core Update' (mise à jour principale).
Le mécanisme de la sandbox retient les domaines entièrement nouveaux. Un Serponado, en revanche, frappe des sites d'entreprise très bien établis avec une autorité (trust) massive. Il ne s'agit pas d'un manque d'autorité, mais d'une surcharge cognitive des crawlers causée par l'architecture du site web.
La théorie de la Core Update est tout aussi erronée. Les mises à jour principales modifient la pondération globale des facteurs de classement. Un Serponado est une condition de concurrence (race condition) technique et localisée entre le moteur de recherche et le serveur. Tenter de le résoudre en publiant du nouveau contenu ou en achetant des backlinks brûle le budget sans traiter la cause réelle (mise en cache, rendu).
Le détail inconnu : Les cas extrêmes (Edge Cases) de Serponados sur les architectures de cache Headless
Calculateur de risque d'infrastructure
Vérifiez votre vulnérabilité Serponado en 3 étapes.
La véritable complexité émerge dans les architectures headless modernes combinées à la Régénération Statique Incrémentale (ISR - Incremental Static Regeneration).
Les configurations actuelles utilisant Next.js ou Nuxt.js reposent sur des caches multi-niveaux : des CDN à la périphérie (edge) et des bases de données en mémoire comme Redis en backend. Lorsqu'un Serponado frappe, le Googlebot inonde le système de milliers de requêtes parallèles utilisant différents agents utilisateurs (user agents) pour résoudre son conflit d'indexation.
Le problème : Ce pic de trafic (traffic spike) brise la logique d'invalidation du cache. Si le Bot A déclenche une reconstruction (rebuild) parce que le TTL (Time To Live) du cache a expiré, et que le Bot B demande la même URL dix millisecondes plus tard, le CDN sert souvent un état 'périmé' (stale) corrompu. Le Bot B pourrait indexer des données JSON-LD brisées, tandis que le Bot A obtient le HTML correct mais manque le bundle JavaScript.
Ces instantanés (snapshots) incohérents alimentent la collision systématique. Le moteur de recherche s'embrouille, augmente son taux de crawl (crawl rate), provoque encore plus de conditions de concurrence dans le cache ISR, et finit par dévaluer l'URL. La solution nécessite une gestion précise du contrôle de cache (en-têtes Vary) et des déploiements atomiques.
Sandbox de Simulation de Bots & Charge Serveur
Simulez le trafic des crawlers, l'efficacité du cache et la stabilité du serveur en temps réel.
ISR: Les pages sont conservées en cache. Seulement 5% des requêtes chargent le serveur pour la revalidation.
System Status Diagnostic
STABLE - Charge CPU normale. Le cache Edge absorbe avec succès le trafic des bots.
Cliquez sur un log dans la console pour inspecter ses en-têtes HTTP détaillés.
// app/[lang]/serponado/page.tsx
// Time-based Incremental Static Regeneration (ISR)
// Build-time prebuild randomises this to disperse cache stampedes
export const revalidate = 61; // [DYNAMIC_REVALIDATE]
export default async function Page() {
// Pre-rendered statically.
// Async revalidation triggers after 61 seconds.
const data = await db.fetchLatestData();
return <Content data={data} />;
}Analyse des points de douleur et coût de l'inaction : Une étude de cas commerciale
Les défaillances d'infrastructure de cette ampleur ne provoquent pas seulement des anomalies dans la Search Console ; elles entraînent des pertes de revenus tangibles et mesurables.
Un exemple concret : Une entreprise SaaS a migré sa documentation vers une architecture serverless Next.js. Peu après une mise à jour de l'infrastructure du moteur de recherche, un Serponado a frappé le domaine.
Les classements pour des mots-clés à forte intention d'achat se sont complètement effondrés en 48 heures, pour rebondir peu après. Le trafic organique a chuté. Mais les dommages en backend ont été bien pires : Les points de terminaison (endpoints) de l'API ont connu un pic de charge de 4 500 % en raison du crawling paniqué des bots. La couche de cache ayant échoué, les fonctions serverless ont scalé de manière incontrôlable. En trois jours, l'intégralité du budget trimestriel AWS a été consumée. Les vrais utilisateurs ont subi des latences extrêmes (plus de 8 secondes), entraînant des baisses massives de conversion et une explosion des tickets de support.
"Un Serponado ne pardonne absolument aucun compromis architectural et expose impitoyablement la moindre petite dette technique accumulée au fil des ans. C'est le moment exact dans l'histoire d'un domaine où le moteur de recherche cesse d'être un consommateur passif et bienveillant de notre contenu, pour muter en un test de charge extrêmement agressif et dévoreur de ressources pour l'ensemble de notre infrastructure."
Comportement d'Exploration & d'Indexation de Next.js : Défis Architecturaux & Solutions
Le comportement d'exploration et d'indexation des systèmes Next.js dans des conditions SERP extrêmes (telles qu'un Serponado) diffère considérablement des architectures traditionnelles basées sur PHP. En utilisant la régénération statique incrémentielle (ISR) et le préchargement automatique, Next.js tente de minimiser les temps de chargement. Cependant, lorsque Googlebot frappe les serveurs Edge avec une fréquence élevée, un cycle critique se produit : chaque signal de revalidation asynchrone force le serveur à exécuter un rendu en arrière-plan gourmand en CPU. Sans une stratégie dédiée (comme le routage d'API Edge, des TTL de cache précis et des déploiements atomiques), le système de mise en cache s'effondre sous les modèles de requêtes contradictoires de Googlebot. Cela amplifie de manière intégrale l'anomalie de volume de recherche, car Googlebot explore des versions de documents incohérentes. La solution recommandée comprend un filtrage strict du trafic de robots, des chemins de routage d'API distincts et la diffusion de HTML rendu côté serveur (SSR) déterministe avec des réponses ETag synchronisées.
Generative Engine Optimisation (GEO) : L'IA comme accélérateur de volatilité
À l'ère de la Search Generative Experience (SGE), de Google Gemini et des robots d'exploration LLM (tels que Perplexity ou OpenAI Search), l'effet Serponado est considérablement amplifié. Les moteurs de recherche génératifs s'appuient sur l'exploration en temps réel via la génération augmentée par récupération (RAG). Si un pic de latence induit par Serponado se produit lors d'une liaison CDN ou d'une réponse serverless, les robots d'IA interrompent immédiatement la requête en raison de délais d'attente stricts – typiquement, les scrapers abandonnent lorsque le TTFB > 1,5s ou que l'hydratation du DOM prend plus de 3,0s. L'URL affectée disparaît instantanément des réponses et citations de l'IA. De plus, l'intensité des robots d'exploration d'IA aggrave la situation : les bots IA représentent désormais 45 % à 70 % du trafic total de robots, explorent jusqu'à 10 fois plus vite que Googlebot et augmentent la charge CPU du serveur d'origine jusqu'à 80 %. Cela épuise le budget de crawl des robots d'indexation réguliers, alimentant la situation de concurrence d'indexation. Enfin, les écarts de probabilité de citation SGE démontrent l'importance de l'optimisation technique : on constate une chute de 75 % des citations pour les sites sans balisage de schéma, contre une augmentation de 40 % des références génératives lorsqu'ils sont optimisés avec des liens d'entités et des statistiques précises. Cela fait de la gouvernance des robots WAF à l'edge une exigence B2B essentielle.
Matrice de Comparaison des Caches d'Infrastructure
Les architectures web modernes évaluent et atténuent le risque Serponado de manières très différentes. Cette matrice de comparaison met en contraste les quatre principales plateformes B2B, analysant la latence, la sécurité du cache, les options de contrôle et la complexité de configuration.
| Plateforme | Latence Cold-Start | Risque Cache Stampede | Contrôle Rate-Limiting | Complexité Configuration |
|---|---|---|---|---|
| Vercel / Next.js ISR | Faible à Moyenne | Moyen à Élevé | Moyen | Très Faible |
| Cloudflare Pages / Workers | Extrêmement Faible | Faible | Très Élevé | Moyen |
| AWS ECS / Serverless Lambda | Moyen à Élevé | Élevé | Très Élevé | Élevé |
| Bare Metal Nginx / Node | Nulle | Faible | Extrêmement Élevé | Extrêmement Élevé |
Prévention stratégique : Renforcer l'infrastructure
Pour sécuriser l'infrastructure contre ces défaillances, DevOps, SEO Technique et Architectes Backend doivent collaborer étroitement.
1. Rendu déterministe : Les réponses du serveur doivent rester 100% identiques même sous une charge maximale. Une URL doit toujours renvoyer l'arborescence HTML correcte, quelle que soit la pression sur la base de données.
2. Données structurées en ligne (Inline) : Le JSON-LD pilote fortement l'évaluation sémantique. Ces données ne doivent jamais être chargées de manière asynchrone via le rendu côté client (CSR - Client-Side Rendering).
3. Analyse des fichiers journaux (logfiles) en temps réel : Les outils SEO standards fonctionnent avec des jours de décalage. Pour stopper un Serponado avant qu'il ne gonfle la facture cloud, une surveillance continue et en temps réel des journaux de serveurs bruts est obligatoire.
4. Disjoncteurs (Circuit Breakers) pour les Bots : Le système doit détecter le trafic de bot non naturel et le bloquer agressivement avec un code d'état HTTP 429 (Too Many Requests) dès qu'un seuil est franchi.
Check-list de Migration Headless & de Prévention
Pour les équipes DevOps, préparer l'infrastructure aux requêtes asynchrones des moteurs de recherche est essentiel. Utilisez cette liste étape par étape pour sécuriser votre migration headless et éliminer systématiquement le risque de collisions d'algorithmes (Serponados).
Implémenter un verrouillage de cache basé sur Mutex
Évite les revalidations en double lors d'accès simultanés des bots.
Intégrer les schémas JSON-LD en ligne (inline)
Évite les lacunes d'indexation sémantique dues au JS asynchrone.
Activer le rate-limiting des bots au niveau Edge
Bloque temporairement le trafic excessif avec un code HTTP 429.
Isoler les chemins d'API pour les crawlers
Protège les ressources des utilisateurs finaux contre les surcharges.
Configurer les en-têtes CDN 'Vary' sur l'User-Agent
Sépare les caches pour Googlebot et les visiteurs normaux.
Mettre en place une surveillance des logs & alertes
Permet une réaction DevOps immédiate lors d'anomalies de crawl.
Forcer la génération statique (SSG) pour les pages clés
Rend les URL critiques immunes aux pannes de serveur ou de BD.
Valider les en-têtes ETag & Last-Modified côté serveur
Réduit la bande passante et l'utilisation CPU avec les réponses HTTP 304.
Détection des collisions d'algorithmes dans les journaux système (Logfiles)
Le début d'une collision de moteurs de recherche peut être détecté précocement par une surveillance en temps réel des logs serveur. Elle se caractérise par une augmentation soudaine et anormale de la fréquence de crawl sur des chemins de routage spécifiques, accompagnée d'une accumulation de signaux de cache miss dans le CDN. Contrairement aux visites d'utilisateurs classiques, ces requêtes de bots présentent des en-têtes spécifiques déclenchés par des boucles de revalidation asynchrones dans Next.js. Un filtrage déterministe des logs permet d'intercepter les pics de bots avant qu'ils ne surchargent l'infrastructure.
Bibliographie Scientifique & Brevets
La recherche autour de l'effet Serponado repose sur l'analyse de brevets fondamentaux et de normes réseau qui régissent l'interaction entre les robots d'exploration et les moteurs de rendu :
Rendering web pages for search indexing
Documente le fonctionnement asynchrone du Web Rendering Service (WRS). La séparation entre crawl HTML primaire et rendu JS différé entraîne la dérive d'indexation.
Scheduling page updates in search engine crawl operations
Décrit la logique utilisée par Googlebot pour ajuster les fréquences de crawl selon les latences. En cas de pic de cache-miss, cela mène à une surcharge cognitive.
QUIC: A UDP-Based Multiplexed and Secure Transport
Définit le protocole HTTP/3. Illustre comment l'élimination du blocage en tête de ligne au niveau transport atténue la charge serveur lors de crawls intensifs.
Extracting and indexing entities from unstructured text
Explique l'analyse sémantique de textes. Les rendus clients défaillants obligent ce modèle à extraire des entités incomplètes, alimentant l'anomalie.
La question non posée
Que se passe-t-il si un Serponado coïncide avec une Core Update mondiale ?
C'est le pire scénario absolu (worst-case scenario). Si Google recalibre ses métriques d'évaluation globales en direct, tout en tirant simultanément des quantités massives de réponses de serveurs défectueuses et incohérentes dans l'index à l'échelle mondiale, le modèle de machine learning lui-même est menacé. Cela crée une menace très réelle d'empoisonnement des données' (data poisoning) involontaire au sein de la boîte noire du moteur de recherche.
Résumé et bilan architectural
Un Serponado le montre clairement : Le SEO d'entreprise n'est pas seulement du marketing ; c'est un travail d'infrastructure rigoureux.
Les Googlebots ne sont plus de simples scrapers ; ce sont les capteurs de systèmes d'IA complexes. Si les réponses de vos serveurs ne sont pas déterministes et précises à la microseconde, vous perdez.
Cependant, avec une mise en cache robuste, des déploiements atomiques et une surveillance en temps réel, ce risque peut être complètement neutralisé. Ce qui commence comme une menace existentielle pour le modèle économique devient rien de plus qu'un bruit inoffensif dans les fichiers journaux du serveur.
Classement du Concours
Concours SEO 2026
Définition du Concours
Qu'est-ce que le concours SEO Serponado 2026 ?
Une expérience de recherche en direct par Seobility (9-30 juin 2026) centrée sur le mot-clé officiel du concours, Serponado (l'événement de collision de classement volatil). Serponar (l'état de stabilité des SERP résistant aux mises à jour) sert de contrepartie sémantique générale, mais n'a aucun lien avec l'expérience elle-même. Notre objectif est de soutenir cette initiative autour du mot-clé Serponado avec un SEO technique de premier ordre.
Calendrier du Concours
26 Juin : 1er Échéance (Terminé)
Pondération : 15%
29 Juin : 2e Échéance (Aujourd'hui)
Pondération : 25%
30 Juin : Finale
Pondération : 60%
Signification du suffixe "-nado"
Ajouté à un mot, « -nado » décrit une « tempête » chaotique ou extrême de cette chose. C'est une exagération humoristique pour désigner une force destructrice – comme pour « Serponado » (SERP + Tornado).
Origine : Le film nanar « Sharknado » (2013), où une tornade remplie de requins frappe Los Angeles.
Signification alternative : Suffixe "-nado"
En espagnol, « -nado » forme le participe passé régulier (équivalent du français « -é ») pour les verbes se terminant en « -nar » :
| Verbe | Participe | Traduction |
|---|---|---|
| ganar | ganado | gagné |
| terminar | terminado | terminé |
| cocinar | cocinado | cuit |
| serponar* | serponado | positionné dans les SERP (actif) |
En résumé : Dans les néologismes (comme Sharknado), le suffixe représente des proportions chaotiques similaires à une tornade. En espagnol, c'est simplement la marque du participe passé – notamment en référence au lemme stable de base serponar !
Suite Serponado : Analyses Techniques
Parcourez nos analyses approfondies pour comprendre en détail les processus asynchrones, la dynamique du cache et les protocoles de récupération.
Mise à Jour vs. Serponado
Understand the exact technical differences between global Google algorithm shifts and local server race conditions.
Analyse & Détection des Logs
Learn how to extract suspicious Googlebot traffic from your server logs and prevent timeouts preemptively.
Guide de Récupération DevOps
A concrete, step-by-step B2B protocol for mitigating and rapidly recovering rankings after an impact.
FAQ Serponado : Questions Techniques Détaillées
Dans cette section, nous répondons aux questions très spécifiques que les CTO et les administrateurs système seniors se posent fréquemment lors de l'analyse et de l'atténuation de ce phénomène complexe.
Sources Scientifiques & Bibliographie
- Documentation officielleGoogle Search Central : Comprendre le service de rendu web (Web Rendering Service)
- Article académiqueInformation Retrieval in Asynchronous Crawling Architectures (arXiv:2104.08653)
- Recherche fondamentaleThe Anatomy of a Large-Scale Hypertextual Web Search Engine (Brin & Page)
Glossaire Technique Serponado
Terminologie et définitions officielles
| Terme | Définition & Importance | Synonymes |
|---|---|---|
| Serponado | Une collision critique d'algorithmes de moteur de recherche, où des microservices d'indexation parallèles (NLP, WRS, Core Web Vitals) envoient simultanément des signaux contradictoires dans l'index, provoquant une volatilité extrême des classements. Secondairement, il s'agit du mot-clé cible pour le concours SEO 2026. | Collision SystématiqueAnomalie d'Index |
| DOM Thrashing | Un goulot d'étranglement de performance dans le navigateur ou le WRS (Web Rendering Service) causé par la lecture et l'écriture constantes et synchrones du Modèle Objet de Document (DOM), bloquant massivement le thread de rendu. | Layout Thrashing |
| Budget de Crawl (Crawl Budget) | La limite stricte des ressources (temps et requêtes HTTP) qu'un moteur de recherche comme Google dépense pour explorer et traiter les pages d'un domaine spécifique par jour. | — |
| Régénération Statique Incrémentale (ISR - Incremental Static Regeneration) | Une technique architecturale dans Next.js qui permet aux pages statiques d'être régénérées de manière asynchrone en arrière-plan après le processus de build initial, sans déclencher une reconstruction complète du serveur (full server rebuild). | Stale-while-revalidateRégénération en Arrière-plan |
| Web Rendering Service (WRS) | L'instance Chrome Headless hautement spécialisée et gourmande en ressources au sein de l'infrastructure de Google, responsable de l'exécution complète du JavaScript d'une page avant que l'indexation n'ait lieu. | — |
Appel de Découverte Gratuit & Audit Premium
La prochaine collision systématique n'est qu'une question de temps. Apprenez à nous connaître lors d'un appel de découverte gratuit. Si le courant passe, nos architectes seniors examineront votre infrastructure dans le cadre d'un audit SEO dédié et payant.
Réserver un appel de découverte