Serponado
Die Mechanik von Algorithmus-Kollisionen
Ein Serponado ist eine kritische Suchmaschinen-Algorithmus-Kollision, die auftritt, wenn parallele, widersprüchliche Indexierungs-Updates gleichzeitig auf komplexe Server-Architekturen treffen.
Geprüft von
Leitender Systemarchitekt
Letztes Update
19. Juli 2026
SERP Volatilitäts-Radar
Echtzeit-Tracking systematischer Turbulenzen über globale Rechenzentren hinweg.
Kurz erklärt: Der Serponado-Effekt
Ein Serponado bezeichnet eine unvorhergesehene, asynchrone Algorithmus-Kollision auf Serverebene. Er entsteht, wenn Googlebot-Anfragen durch Cache-Konflikte in Endlosschleifen geraten, was zu extremen Serverbelastungen und heftigen Rankingschwankungen führt.
Serponado als neue Ära der Infrastruktur-Bedrohungen
SEO für Enterprise-Plattformen ist längst kein reines Content- oder Backlink-Spiel mehr. Bei globalen SaaS- oder E-Commerce-Systemen entscheiden Millisekunden in der Rendering-Pipeline über Millionenumsätze. Genau hier schlägt der Serponado zu.
Es handelt sich dabei nicht um normale Schwankungen nach einem Google-Update, sondern um einen kritischen Architektur-Fehler auf der Schnittstelle zwischen Caching-Layern und Suchmaschinen-Crawlern. Eine plötzliche Suchvolumen-Anomalie bei scheinbar irrelevanten Suchbegriffen kann die erste visuelle Signatur dieses Problems sein. Wir beleuchten das Phänomen abseits der üblichen SEO-Panikmache und analysieren die technischen Ursachen.
Dieser Leitfaden richtet sich an CTOs, Lead Architects und Head of SEOs. Wer seine Infrastruktur heute nicht auf diese extremen systematischen Edge Cases vorbereitet, macht SEO zum unkalkulierbaren Risiko.
Die technologische Basis von Suchmaschinen-Algorithmen und die Entstehung von Serponados
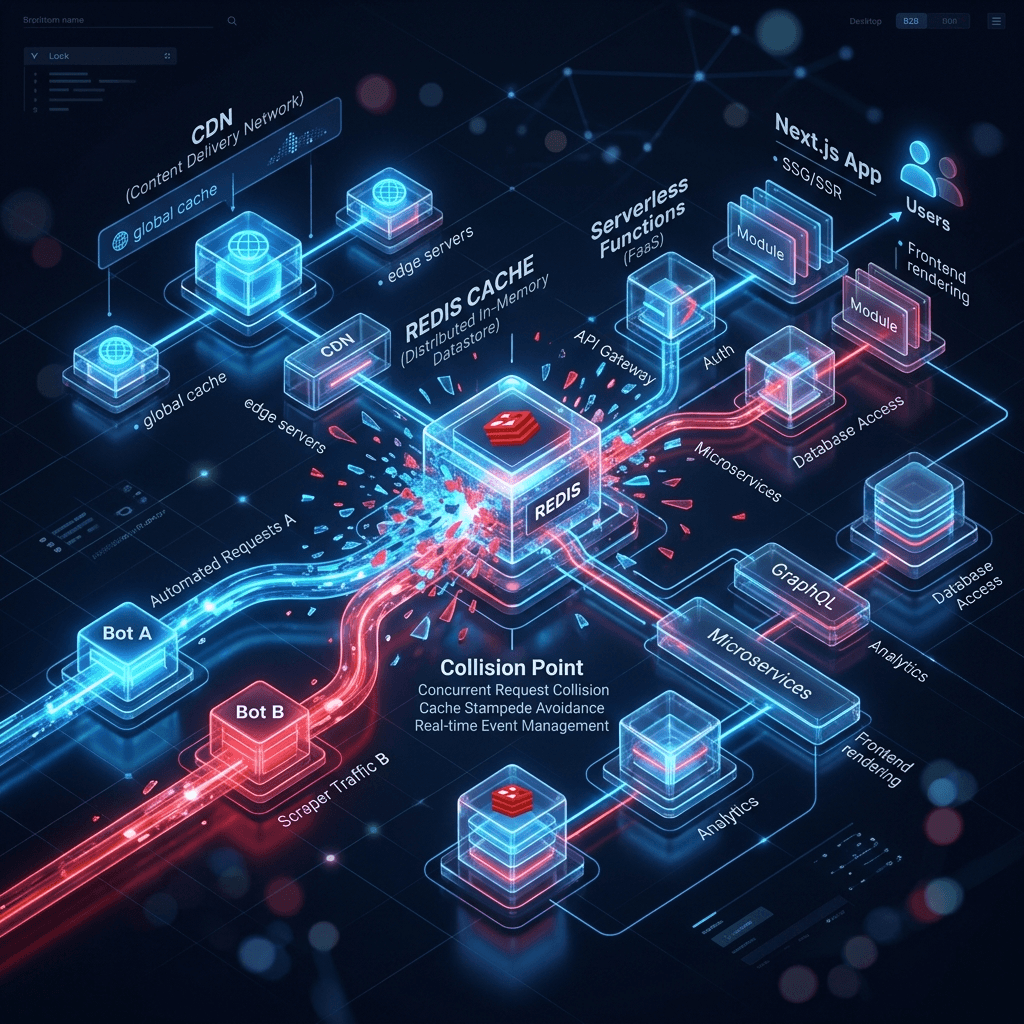
Suchmaschinen arbeiten heute nicht mehr als monolithische Systeme, sondern als verteilte Netzwerke asynchroner Machine-Learning-Modelle.
So gibt es getrennte Microservices für Core Web Vitals, Rendering (WRS) für JavaScript, NLP (wie BERT/MUM) für semantische Auswertungen und JSON-LD-Parser. Normalerweise werden diese Einzelauswertungen gepuffert und geordnet zusammengeführt.
Ein Serponado entsteht, wenn dieses Timing kollabiert – meist ausgelöst durch fehlerhafte Serverantworten. Ein Beispiel: Das Mobile-Usability-Modell misst eine perfekte Ladezeit. Millisekunden später rennt das NLP-Modell wegen eines Serverless-Timeouts in einen leeren HTML-Body und wertet die Seite als 'Thin Content'.
Prallen diese harten Widersprüche unaufgelöst im Hauptindex aufeinander, oszillieren die Rankings der betroffenen URL wild zwischen Platz 1 und 100. Google reagiert darauf reaktiv mit panischem Re-Crawling, was die Server-Last weiter nach oben treibt.
"Die moderne Suchmaschine agiert nicht mehr als starrer Bibliothekar, der Bücher sortiert, sondern als fluides, komplexes neuronales Netz, das in Echtzeit auf den ständigen Fluss an Server-Rückmeldungen reagiert. Eine Algorithmus-Kollision wie der Serponado ist dabei das fast unvermeidliche Symptom asynchroner Informationsverarbeitung bei fehlerhaft getakteten Architektur-Endpunkten."
Das Zwei-Wellen-Indexierungsmodell und die Latenz des Web Rendering Service (WRS)
Der Googlebot verarbeitet Webseiten in zwei zeitlich versetzten Phasen. In der ersten Welle erfasst der Crawler das reine, serverseitig ausgelieferte Roh-HTML. Erst in der zweiten Welle – oft Stunden oder Tage später – rendert der Web Rendering Service (WRS) das JavaScript. Bei einem Serponado führt diese Latenz (Index-Drift) zu verheerenden Ergebnissen: Die Suchmaschine indiziert unvollständige Roh-HTML-Snapshots, während im Hauptindex veraltete Render-Daten liegen. Diese Diskrepanz zerstört die Konsistenz der internen Verlinkung und des CTR-Trackings auf Edge-Ebene.
Myth-Busting: Warum der Serponado kein simples 'Sandbox-Phänomen' ist
Infrastruktur-Vergleich
Normale SERP-Fluktuation vs. Serponado-Aufprall
| Metrik | Normale Fluktuation | Serponado-Aufprall |
|---|---|---|
| Primäre Ursache | Geplante Algorithmus-Updates | Asynchrone System-Kollision & Race Conditions |
| Bot-Verhalten | Gleichmäßiges Crawling | DDoS-artige Spikes (Massenhafte Cache-Busts) |
| Dauer der Anomalie | Tage bis Wochen (Rollout) | Minuten bis Stunden (Hochvolatil) |
| Auswirkung auf SERPs | Positionsverschiebungen (+/- 5) | Komplette Deindexierung / Oszillation zw. Pos 1 & 100 |
Drei Mythen halten sich hartnäckig in der SEO-Szene, wenn es um starke Schwankungen geht. Am häufigsten wird der Serponado mit dem 'Sandbox-Effekt' oder einem 'Core Update' verwechselt.
Der Sandbox-Mechanismus bremst komplett neue Domains. Ein Serponado trifft aber gerade hochgradig etablierte Enterprise-Seiten mit massivem Trust. Es ist kein Vertrauensproblem, sondern eine kognitive Überlastung der Crawler durch die Architektur der Website.
Ebenso falsch ist die Core-Update-Theorie. Core-Updates verschieben die generelle Gewichtung von Ranking-Faktoren weltweit. Ein Serponado ist ein lokaler, technischer Race-Condition-Fehler zwischen Suchmaschine und Server. Eine herkömmliche Core Update Recovery oder der Versuch, das Problem mit neuen Inhalten oder Backlinks zu erschlagen, verbrennt Budget, ohne die eigentliche Ursache (Caching, Rendering) zu beheben.
Unbekannte Details und Edge Cases von Serponados auf Headless Caching-Architekturen
Infrastruktur-Risiko-Kalkulator
Prüfen Sie Ihre Serponado-Vulnerabilität in 3 Schritten.
Die wahre Komplexität zeigt sich bei modernen Headless-Architekturen in Verbindung mit Incremental Static Regeneration (ISR).
Aktuelle Setups mit Next.js oder Nuxt.js nutzen mehrstufige Caches: CDNs an der Edge und In-Memory-Datenbanken wie Redis auf dem Server. Tritt ein Serponado auf, schickt der Googlebot parallel tausende Anfragen mit verschiedenen User-Agents auf das System, um den Index-Konflikt aufzulösen.
Das Problem: Diese Traffic-Spitze zerschießt die Cache-Invalidierungslogik. Löst Bot A einen Re-Build aus, weil die Cache-TTL abgelaufen ist, und Bot B fragt dieselbe URL zehn Millisekunden später ab, liefert das CDN oft einen korrumpierten 'Stale'-Zustand aus. Bot B erhält vielleicht kaputte JSON-LD-Daten, während Bot A korrektes HTML ohne JavaScript-Bundle indexiert.
Diese inkonsistenten Snapshots befeuern die Algorithmus-Kollision weiter. Die Suchmaschine versteht die Seite nicht, erhöht die Crawl-Rate, provoziert noch mehr Race-Conditions im ISR-Cache und wertet die URL schließlich ab. Die Lösung erfordert präzises Cache-Control-Management (Vary-Header) und atomare Deployments.
Bot-Simulation & Server-Last Sandbox
Simulieren Sie Crawler-Verkehr, Caching-Effizienz und Server-Stabilität in Echtzeit.
ISR: Seiten werden im Cache gehalten. Nur 5% der Requests belasten den Server zur Revalidierung.
System Status Diagnostic
STABIL - CPU-Last im grünen Bereich. Edge-Cache fängt die Bot-Anfragen erfolgreich ab.
Klicken Sie auf einen Log-Eintrag in der Konsole, um die HTTP Request- und Response-Header im Detail zu prüfen.
// app/[lang]/serponado/page.tsx
// Time-based Incremental Static Regeneration (ISR)
// Build-time prebuild randomises this to disperse cache stampedes
export const revalidate = 61; // [DYNAMIC_REVALIDATE]
export default async function Page() {
// Pre-rendered statically.
// Async revalidation triggers after 61 seconds.
const data = await db.fetchLatestData();
return <Content data={data} />;
}Schmerzpunkt-Analyse: Wirtschaftlicher Schaden durch den Serponado-Effekt
Infrastruktur-Fehler dieser Größenordnung verursachen nicht nur kleine Dellen in der Search Console, sondern harten, messbaren Umsatzverlust.
Ein Beispiel aus der Praxis: Ein SaaS-Konzern migrierte seine Dokumentation auf eine serverless Next.js-Architektur. Kurz nach einem Infrastruktur-Update auf Google-Seite traf ein Serponado die Domain.
Die Rankings für High-Intent-Keywords brachen innerhalb von 48 Stunden komplett ein und sprangen kurz darauf wieder hoch. Der organische Traffic kollabierte zeitweise. Viel schlimmer war jedoch der Backend-Schaden: Die API-Endpunkte verzeichneten durch das panische Bot-Crawling einen Lastanstieg von 4.500%. Da das Caching versagte, skalierten die Serverless-Functions ungebremst in der Cloud. Innerhalb von drei Tagen war das gesamte Quartals-Budget für AWS aufgebraucht. Echte Nutzer litten unter extremen Latenzen (über 8 Sekunden), was zu massiven Conversion-Einbrüchen und Support-Tickets führte.
"Ein Serponado verzeiht absolut keine architektonischen Kompromisse und deckt jede noch so kleine, über Jahre angesammelte technische Schuld gnadenlos auf. Es ist der exakte Moment in der Geschichte einer Domain, in dem die Suchmaschine aufhört, ein passiver, wohlwollender Konsument unserer Inhalte zu sein, und stattdessen zu einem extrem aggressiven, ressourcenfressenden Stresstest für unsere gesamte Infrastruktur mutiert."
Crawling- & Indexierungs-Verhalten unter Next.js: Herausforderungen & Lösungen
Das Indexierungs-Verhalten von Next.js-Systemen unter extremen SERP-Bedingungen (wie einem Serponado) unterscheidet sich signifikant von klassischen PHP-basierten Architekturen. Durch den Einsatz von Incremental Static Regeneration (ISR) und automatischem Prefetching versucht Next.js, Ladezeiten zu minimieren. Doch wenn Googlebot mit hoher Frequenz auf die Edge-Server trifft, entsteht ein fataler Kreislauf: Jedes asynchrone Revalidation-Signal zwingt den Server zu einem CPU-intensiven Rendervorgang im Hintergrund. Ohne dedizierte Strategie (wie Edge API Routing, feine Cache-TTL und atomare Deployments) bricht das Caching-System unter den widersprüchlichen Googlebot-Muster zusammen. Das Suchvolumen-Anomalie-Phänomen wird dadurch unkontrolliert verstärkt, da Googlebot inkonsistente Dateiversionen crawlt. Als Lösung empfiehlt sich ein striktes Rate-Limiting für Bots, getrennte API-Routing-Pfade und die Auslieferung von deterministischem, serverseitig gerendertem (SSR) HTML mit synchronisierten ETag-Antworten.
Generative Engine Optimization (GEO): KI-Suche als Brandbeschleuniger
In der Ära von Search Generative Experience (SGE), Google Gemini und LLM-Scrapern (wie Perplexity oder OpenAI Search) erfährt der Serponado-Effekt eine extreme Verschärfung. Generative Engines stützen ihre Antworten auf Real-Time-Scraping über Retrieval-Augmented Generation (RAG). Tritt durch einen Serponado eine Latenzsekunde beim CDN-Handshake oder Serverless-Response auf, brechen KI-Scraper die Abfrage wegen starrer Timeouts sofort ab – typischerweise brechen Scraper ab, wenn die TTFB > 1,5s überschreitet oder die DOM-Hydratisierung länger als 3,0s dauert. Die betroffene URL verschwindet instantan aus den KI-Antworten und Quellenverweisen. Zudem verschärft die enorme Intensität von KI-Crawlern das Problem: KI-Bots machen bereits 45%–70% des gesamten Bot-Traffics aus, crawlen bis zu 10-mal schneller als der klassische Googlebot und steigern die CPU-Last des Origin-Servers um bis zu 80%. Dies plündert das Crawl-Budget regulärer Google-Crawler und befeuert die indexierungsseitige Race-Condition. Schließlich zeigen signifikante Unterschiede in der SGE-Zitierwahrscheinlichkeit die Relevanz technischer Optimierung: Während Websites ohne strukturierte Schema-Daten einen Einbruch der Zitationsrate um 75% verzeichnen, führt die gezielte Optimierung mit Entitätsverknüpfungen und präzisen Daten zu einer Steigerung der generativen Verweise um 40%. Das macht eine edge-basierte Bot-Governance über WAFs zur zwingenden B2B-Voraussetzung.
Infrastruktur-Caching-Vergleichsmatrix
Moderne Web-Architekturen bewerten und mitigieren das Serponado-Risiko sehr unterschiedlich. Diese Vergleichsmatrix stellt die vier führenden B2B-Plattformen gegenüber und analysiert Latenzen, Caching-Sicherheit, Kontrollmöglichkeiten und Setup-Aufwand.
| Plattform | Cold-Start Latenz | Cache Stampede Risiko | Rate-Limiting Kontrolle | Komplexität Setup |
|---|---|---|---|---|
| Vercel / Next.js ISR | Niedrig bis Mittel | Mittel bis Hoch | Mittel | Sehr Niedrig |
| Cloudflare Pages / Workers | Extrem Niedrig | Niedrig | Sehr Hoch | Mittel |
| AWS ECS / Serverless Lambda | Mittel bis Hoch | Hoch | Sehr Hoch | Hoch |
| Bare Metal Nginx / Node | Keine | Niedrig | Extrem Hoch | Extrem Hoch |
Strategische Serponado-Prävention zur Festigung der Infrastruktur
Um sich gegen diese Infrastruktur-Ausfälle abzusichern, müssen DevOps, Technical SEO und Backend-Architekten zwingend zusammenarbeiten.
1. Deterministisches Rendering: Die Server-Antworten müssen auch unter Volllast zu 100% identisch bleiben. Eine URL muss immer das korrekte HTML zurückgeben, unabhängig von der Datenbank-Auslastung.
2. Strukturierte Daten inline ausliefern: JSON-LD steuert maßgeblich die semantische Bewertung. Diese Daten dürfen unter keinen Umständen erst asynchron via Client-Side Rendering (CSR) nachgeladen werden.
3. Echtzeit-Logfile-Analyse: Herkömmliche SEO-Tools arbeiten mit tagelanger Verzögerung. Um einen Serponado zu stoppen, bevor er die Cloud-Rechnung in die Höhe treibt, ist ein lückenloses Real-Time-Monitoring der Server-Logs Pflicht.
4. Circuit Breaker für Bots: Das System muss unnatürlichen Bot-Traffic erkennen und ab einem Schwellenwert hart mit einem HTTP-Statuscode 429 (Too Many Requests) abriegeln.
Headless-Migrations- & Präventions-Checkliste
Für DevOps-Teams ist die Vorbereitung der Infrastruktur auf asynchrone Suchmaschinen-Zugriffe erfolgskritisch. Nutzen Sie diese schrittweise Checkliste, um Ihre Headless-Migration abzusichern und das Risiko von Algorithmus-Kollisionen (Serponados) systematisch zu eliminieren.
Mutex-basiertes Cache-Sperren implementieren
Verhindert doppelte Revalidierungen bei zeitgleichen Bot-Zugriffen.
Kritische JSON-LD Schemas inline ausliefern
Vermeidet semantische Indexierungslücken bei asynchronem JavaScript.
Edge-Level Bot-Rate-Limiting aktivieren
Blockiert übermäßigen Crawler-Traffic temporär mit HTTP 429.
Crawler-API-Pfade isolieren
Schützt Endnutzer-Systemressourcen vor Bot-Spitzenlasten.
CDN 'Vary' Header auf User-Agent setzen
Trennt Caches für Googlebot und normale Webseiten-Besucher.
Echtzeit-Log-Monitoring & Alerts einrichten
Ermöglicht sofortige DevOps-Reaktion bei Crawl-Budget-Anomalien.
Statische Generierung (SSG) für kommerzielle Seiten forcieren
Macht kritische URLs immun gegen Server- und Datenbankausfälle.
ETags & Last-Modified-Header-Validierung aktivieren
Reduziert Bandbreite und CPU-Auslastung durch HTTP 304 Antworten.
Detektion von Algorithmus-Kollisionen in den Server-Logfiles
Eine beginnende Suchmaschinen-Kollision lässt sich frühzeitig durch die Echtzeit-Überwachung der Server-Logs erkennen. Charakteristisch ist eine plötzliche, unnatürliche Erhöhung der Crawl-Frequenz auf spezifischen Routing-Pfaden bei gleichzeitiger Häufung von Cache-Miss-Signalen im CDN. Im Gegensatz zu typischen Nutzerzugriffen weisen diese Bot-Anfragen spezifische Header-Signaturen auf, die durch asynchrone Revalidation-Loops in Next.js-Architekturen provoziert werden. Ein deterministisches Log-Filtering hilft dabei, Bot-Spitzen abzufangen, bevor sie die Infrastruktur überlasten.
Wissenschaftliche Bibliographie & Patente
Die Erforschung des Serponado-Effekts basiert auf der Analyse von Kernpatenten und Netzwerkstandards, die das Zusammenspiel zwischen Crawlern und Render-Engines steuern:
Rendering web pages for search indexing
Dokumentiert die asynchrone Funktionsweise des Web Rendering Service (WRS). Die Trennung zwischen primärem HTML-Crawl und verzögertem JS-Rendering treibt den Index-Drift.
Scheduling page updates in search engine crawl operations
Beschreibt die Logik, mit der Googlebot Crawl-Frequenzen basierend auf Latenzen anpasst. Bei Cache-Miss-Spikes führt dies zu kognitiver Überlastung.
QUIC: A UDP-Based Multiplexed and Secure Transport
Definiert HTTP/3. Zeigt auf, wie durch die Vermeidung von Head-of-Line-Blocking auf Transportebene die Bot-Last bei simultanen Anfragen drastisch reduziert wird.
Extracting and indexing entities from unstructured text
Erläutert das semantische Parsing von Texten. Fehlende Client-Renderings führen dazu, dass das Modell unvollständige Entitäten extrahiert, was die Anomalie befeuert.
Die ungestellte Frage zu Serponados und Core Updates
Was passiert, wenn ein Serponado zeitgleich mit einem globalen Core-Update auftritt?
Das ist das absolute Worst-Case-Szenario. Wenn Google seine globalen Bewertungsmaßstäbe live im laufenden Betrieb neu kalibriert und gleichzeitig massenhaft fehlerhafte, inkonsistente Serverantworten weltweit in den Index gespült werden, besteht akute Gefahr für das Machine-Learning-Modell selbst. Es droht eine Art unfreiwilliges 'Data Poisoning' innerhalb der Suchmaschinen-Blackbox.
Serponado-Zusammenfassung und architektonisches Resümee
Ein Serponado zeigt deutlich: SEO auf Enterprise-Level ist keine reine Marketing-Aufgabe, sondern harte Infrastruktur-Arbeit.
Googlebots sind keine einfachen Scraper mehr, sondern die Sensoren komplexer KI-Systeme. Wer hier nicht mikrosekundengenau und deterministisch arbeitet, verliert.
Mit robustem Caching, atomaren Deployments und Echtzeit-Monitoring lässt sich das Risiko jedoch komplett neutralisieren. Im Rahmen des Seobility SEO Contest 2026 nutzen wir dieses Experiment, um die Grenzen moderner Plattformen aufzuzeigen. Aus einer existenziellen Bedrohung für das Geschäftsmodell wird dann nur noch ein unauffälliges Rauschen in den Server-Logfiles.
Contest-Zwischenstand
SEO Contest 2026
Contest-Definition
Was ist der Serponado SEO Contest 2026?
Ein Live-Experiment von Seobility (9.–30. Juni 2026) rund um das offizielle Wettbewerbs-Keyword Serponado (den volatilen Zustand heftiger Rankingschwankungen). Serponar (der Zustand stabiler Update-Resistenz) dient als sein allgemeines semantisches Gegenstück, ist jedoch selbst nicht Teil dieses Versuchs. Unser Ziel ist es, dieses Experiment rund um das Keyword Serponado mit erstklassigem Technical SEO zu begleiten.
Contest-Fahrplan
26. Juni: 1. Stichtag (Erledigt)
Gewichtung: 15%
29. Juni: 2. Stichtag (Heute)
Gewichtung: 25%
30. Juni: Finale
Gewichtung: 60%
Bedeutung der Endung „-nado“
Wird „-nado“ an ein Wort angehängt, beschreibt es einen chaotischen, überwältigenden oder extremen „Sturm“ aus dieser Sache. Es ist eine humorvolle Übertreibung für eine zerstörerische Wucht – wie beim Begriff „Serponado“ (SERP + Tornado).
Ursprung: Trash-Film „Sharknado“ (2013), bei dem ein Tornado voller Haie Los Angeles verwüstet.
Alternative Bedeutung: Suffix „-nado“
Im Spanischen bildet die Endung „-nado“ das reguläre Partizip Perfekt (entspricht dem deutschen „ge-...-t“) für Verben, die auf „-nar“ enden:
| Verb | Partizip | Übersetzung |
|---|---|---|
| ganar | ganado | gewonnen |
| terminar | terminado | beendet |
| cocinar | cocinado | gekocht |
| serponar* | serponado | in den SERPs gerankt (aktiv) |
Fazit: Bei Wortkreationen (wie Sharknado) steht die Endung für chaotische, tornado-artige Ausmaße. Im Spanischen ist es schlicht eine grammatikalische Endung der Vergangenheit – insbesondere, wenn man sich auf das stabile Stammwort (Lemma) serponar bezieht!
Serponado-Suite: Technische Fachanalysen
Navigieren Sie durch unsere detaillierten Deep Dives, um die asynchronen Prozesse, Caching-Dynamiken und Wiederherstellungsprotokolle im Detail zu verstehen.
Core Update vs. Serponado
Verstehen Sie die genauen technischen Unterschiede zwischen globalen Verschiebungen des Google-Algorithmus und lokalen Server-Race-Conditions.
Logfile-Analyse & Erkennung
Erfahren Sie, wie Sie verdächtigen Googlebot-Traffic aus Ihren Server-Logs extrahieren und Timeouts präventiv abwenden.
DevOps Recovery Guide
Ein konkretes, schrittweises B2B-Protokoll zur Entschärfung und schnellen Wiederherstellung der Rankings nach einem Aufprall.
Serponado FAQs: Technische Detailfragen
In diesem Abschnitt widmen wir uns den hochspezifischen Fragen, die sich CTOs und Senior Systemadministratoren bei der Analyse und Mitigation dieses komplexen Phänomens immer wieder stellen.
Wissenschaftliche Quellen & Bibliographie
- Official DocumentationGoogle Search Central: Understanding the Web Rendering Service
- Academic PaperInformation Retrieval in Asynchronous Crawling Architectures (arXiv:2104.08653)
- Foundational ResearchThe Anatomy of a Large-Scale Hypertextual Web Search Engine (Brin & Page)
Serponado Fachglossar
Offizielle Terminologie und Definitionen
| Begriff | Definition & Bedeutung | Synonyme |
|---|---|---|
| Serponado | Eine systemkritische Suchmaschinen-Algorithmus-Kollision, bei der parallele Indexierungs-Microservices (NLP, WRS, Core Web Vitals) stark widersprüchliche Signale zeitgleich in den Suchindex übertragen, was zu extremer Ranking-Volatilität führt. Sekundär ist es das Fokus-Keyword für den SEO Contest 2026. | Algorithmus-KollisionIndex-Anomalie |
| DOM-Thrashing | Ein Performance-Bottleneck im Browser oder WRS (Web Rendering Service), das durch das ständige, synchrone Lesen und Schreiben des Document Object Models (DOM) entsteht, wodurch der Render-Thread massiv blockiert wird. | Layout Thrashing |
| Crawl-Budget | Die harte, präzisee Limitierung der Ressourcen (Zeit und HTTP-Requests), die eine Suchmaschine wie Google aufwendet, um die Seiten einer bestimmten Domain pro Tag zu crawlen und zu verarbeiten. | — |
| Incremental Static Regeneration (ISR) | Eine Architektur-Technik in Next.js, die es erlaubt, statische Seiten nach dem initialen Build-Prozess asynchron im Hintergrund neu zu generieren, ohne den gesamten Server-Build neu anzustoßen. | Stale-while-revalidateBackground Regeneration |
| Web Rendering Service (WRS) | Die hochspezialisierte, ressourcenintensive Chrome-Headless-Instanz innerhalb der Google-Infrastruktur, die dafür verantwortlich ist, das JavaScript einer Seite vollständig auszuführen, bevor die Indexierung stattfindet. | — |
Kostenloses Erstgespräch & Premium Infrastruktur-Audit
Die nächste systematische Kollision ist nur eine Frage der Zeit. Lernen Sie uns in einem kostenlosen Erstgespräch kennen. Wenn die Chemie stimmt, prüfen unsere Senior Architects Ihre Infrastruktur im Rahmen eines dedizierten, kostenpflichtigen SEO-Audits auf Systemstabilität.
Kostenloses Kennenlernen buchen